多语言文本语义特征提取 - SDK【支持多语言】
多语言文本语义特征提取工具箱提供3个SDK, 满足对不同语言,不同精度,不同速度等场景的需要。 文本语义特征提取是指从文本数据中提取出具有语义信息的关键特征的过程,最后生成特征向量。这些特征向量可以帮助计算机更好地理解文本内容,进行分类、聚类、检索、摘要等任务。文本语义特征提取具体应用有:
- 语义搜索,通过句向量相似性,检索语料库中与查询语句最匹配的文本。
- 文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本。
- 文本分类,表示成句向量,直接用简单分类器即训练文本分类器。
- 特征向量提取
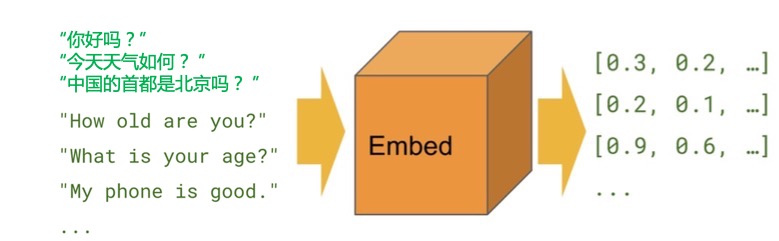
多语言文本语义特征提取工具箱提供 3 个 SDK:
- sentence_encoder_15_sdk(支持 15 种语言)
- sentence_encoder_100_sdk(支持100种语言)
- text2vec_base_multilingual_sdk(支持50+种语言)
SDK功能:
- 句向量提取
- 相似度(余弦)计算
应用场景 – 文本语义搜索原理简介
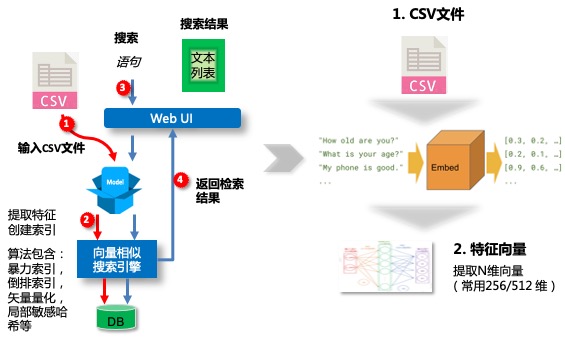
文本搜索,具体过程都分为两个阶段:
首先是文本入库,文本入库主要包含两个步骤,文本特征提取,以及文本特征入库,也就是存入向量数据库。
第二阶段是文本语义搜索。首先输入文本,然后系统会提取文本的特征,最后根据特征值去向量数据库进行检索,获取相似度最高的一组文本,并返回搜索结果。
应用场景 – 用于RAG大模型领域
文本搜索是一种通过在文本数据集中查找特定关键词、短语或模式来定位信息的技术。它在各种领域中都有广泛的应用,包括搜索引擎、信息检索、自然语言处理、数据挖掘等。在RAG,即检索增强生成模型中,文本搜索起着关键作用,以下是文本搜索在检索增强生成中的应用介绍:
- 信息检索:检索增强生成结合了检索和生成两种方法,通过文本搜索技术可以快速从大规模文本数据中检索相关信息。在生成阶段,检索增强生成可以利用检索到的信息来辅助生成更加相关和准确的文本。
- 上下文理解:文本搜索可以帮助大模型更好地理解上下文。通过搜索相关文本片段,大模型可以获取更多背景知识和语境信息,从而生成更加连贯和合理的文本。
- 知识获取:大模型通常结合了预训练的语言模型和文本检索模块,可以利用文本搜索技术从外部知识库或大规模文本数据中获取知识。这些知识可以被整合到生成的文本中,使生成的内容更加丰富和准确。
- 答案生成:在问答系统中,文本搜索可以帮助大模型找到与问题相关的信息。大模型可以首先通过文本搜索找到可能包含答案的文本片段,然后再基于这些文本片段生成最终的答案。
- 对话系统:在对话生成任务中,文本搜索可以用来检索历史对话记录或相关知识,帮助大模型更好地理解用户输入并生成更加合适的回复。
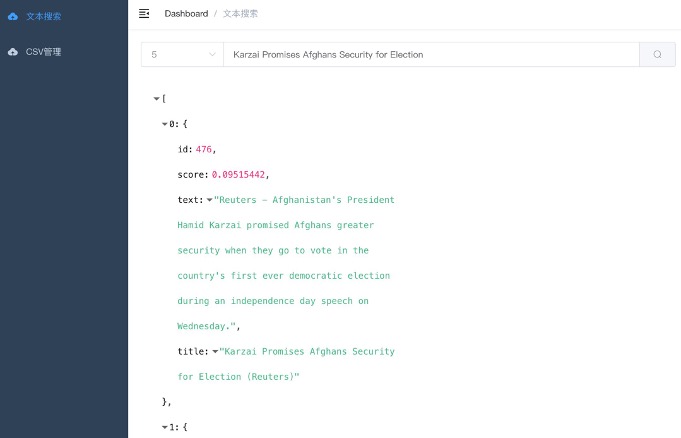
运行例子 - SentenceEncoderExample
运行成功后,命令行应该看到下面的信息:
x...# 测试语句:# 英文一组[INFO ] - input Sentence1: This model generates embeddings for input sentence[INFO ] - input Sentence2: This model generates embeddings
# 中文一组[INFO ] - input Sentence3: 今天天气不错[INFO ] - input Sentence4: 今天风和日丽
# 向量维度:[INFO ] - Vector dimensions: 768
# 英文 - 生成向量:[INFO ] - Sentence1 embeddings: [0.10717804, 0.0023716218, ..., -0.087652676, 0.5144994][INFO ] - Sentence2 embeddings: [0.06960095, 0.09246655, ..., -0.06324193, 0.2669841]
#计算英文相似度:[INFO ] - 英文 Similarity: 0.84808713
# 中文 - 生成向量:[INFO ] - Sentence1 embeddings: [0.19896796, 0.46568888,..., 0.09489663, 0.19511698][INFO ] - Sentence2 embeddings: [0.1639189, 0.43350196, ..., -0.025053274, -0.121924624]
#计算中文相似度:#由于使用了sentencepiece切词器,中文切词更准确,比15种语言的模型(只切成字,没有考虑词)精度更好。[INFO ] - 中文 Similarity: 0.67201
项目源码的使用说明
- 提供完整的java语言实现的项目源代码(含模型文件),如果是web应用,前端VUE,后端SpringBoot
- 可用于自我学习目的,其它帮助信息参考:http://aias.top/guides.html
- 可用于项目中,在现有的代码上定制开发,减少从零开始的摸索时间。